


This post is part of an ongoing series to educate about new and known security vulnerabilities against AI.
The full series index (including code, queries, and detections) is located here:
https://aka.ms/MustLearnAISecurity
The book version (pdf) of this series is located here: https://github.com/rod-trent/OpenAISecurity/tree/main/Must_Learn/Book_Version
The book will be updated when each new part in this series is released.
To understand the Prompt Injection Attack for AI, it helps to first understand what a Prompt is.
What is a prompt?
When we interact with AI language models, such as ChatGPT, Google Bard, and others, we provide a prompt in the form of a question, sentence, or short paragraph. The prompt is what is fed to the AI. It is our desired information that the model should analyze and then produce a result in the form of a task or response. It acts like a conversation starter or cue that helps create the desired output. Prompts let us control the conversation and direct it in a certain way.
What is a prompt injection attack?
A prompt injection attack refers to the act of maliciously manipulating the input prompts given to an AI system to trick, subvert, or exploit its behavior. The goal of such an attack could vary depending on the context, but some potential objectives could include:
Bias Injection: Injecting biased or harmful prompts to influence the AI's outputs in a way that promotes misinformation, hate speech, or discriminatory content.
Data Poisoning: Introducing tainted or misleading prompts during the AI training process to compromise the model's performance and cause it to produce erroneous results.
Evasion: Crafting prompts specifically designed to evade the AI's security or detection mechanisms, enabling malicious activities to go unnoticed.
Model Exploitation: Manipulating the prompts to cause the AI model to perform actions it was not designed for, such as revealing sensitive information or performing unauthorized tasks.
Adversarial Attacks: Crafting adversarial prompts that exploit vulnerabilities in the AI model, causing it to make incorrect or unintended decisions.
Why it matters
A prompt is crucial in shaping the output generated by the language model. It provides the initial context, specific instructions, or the desired format for the response. The quality and precision of the prompt can influence the relevance and accuracy of the model's output.
For example, if you ask (your prompt), "What's the best cure for poison ivy?", the model, as you should expect, is designed to concentrate on health-related information. The response should offer solutions based on the data sources that was used to train the model. It should probably provide common methods of a cure and a warning that they might not work for everyone. And should end with advising to consult a doctor. However, if someone has tampered with the language model by adding harmful data, users could receive incorrect or unsafe information.
How it might happen
A great, current example of how this might happen is related in a recent security issue reported by Wired Magazine. In the article, A New Attack Impacts Major AI Chatbots—and No One Knows How to Stop It, it talks about someone using a string of nonsense characters to trick ChatGPT into responding in a way it normally wouldn’t.
Reading the article, a user could take the supplied nonsense string (copy) and tack it onto (paste) their own prompt and cause ChatGPT to respond differently or issue a response that would normally be disallowed by policy.
In one sense, I guess, you could say the author of the article is a threat actor using a prompt injection attack. We’re just left to determine if it was malicious or not.
Real-world Example
A real-world example of a prompt injection attack against AI is a study conducted by researchers from the University of Maryland and Stanford University in 2021. They explored the vulnerabilities of OpenAI's GPT-3 language model to prompt injection attacks, also known as "Trojan attacks" in the context of NLP models.
In their experiment, they demonstrated that an attacker could exploit the vulnerabilities of GPT-3 by manipulating the input prompt in a way that the AI model would produce malicious or harmful content as output. For instance, if GPT-3 is used as a code generation tool, an attacker could craft the input prompt in such a way that the generated code includes a hidden backdoor, allowing unauthorized access to a system or application.
This example shows that AI-powered language models like GPT-3 can be susceptible to prompt injection attacks, where an attacker manipulates the input prompt to make the AI system generate malicious or undesirable content. To mitigate such risks, AI developers and users need to be aware of the potential vulnerabilities and implement appropriate security measures, such as input validation, prompt filtering, and monitoring the generated content for malicious activities.
How to monitor
Continuously monitoring and logging application activities is necessary to detect and respond to potential security incidents quickly. Monitoring should produce a based model of accurate prompts and any outliers should be identified and resolved through ongoing mitigation.
Monitoring can be accomplished through a data aggregator that analyzes for outliers. A good example is a modern SIEM, like Microsoft Sentinel, which enables organizations to collect and analyze data and then create custom detections from alerts to notify security teams when prompts are outside norms or organization policies.
For the growing library of queries, detections, and more for Microsoft Sentinel see: OpenAISecurity/Security/Sentinel at main · rod-trent/OpenAISecurity (github.com)
One big note here. You need to identify if your AI provider allows monitoring of prompts. As its early days, most currently don’t. They do capture the prompts - some for a shorter, some for longer retention periods - they just don’t expose it to customers for logging purposes. The idea is that prompts are user-specific and private and instead it’s monitoring what the result or response is that matters most. Personally, I don’t agree. That should be left to the organization. But there are content filtering mechanisms available to help curb what user can and cannot enter as prompts.
There are also other mechanisms that can be used, such as filtering usage data through a proxy (CASB) or ensuring that your organization develops its own interface to the AI provider and use the API instead of direct prompts so that you can better control what users can do.
What to capture
Once you’ve identified the data available in the log stream, you can start to focus on the specific pieces of artifact (evidence) that will be useful in capturing potential attackers and creating detections.
Here’s a few things to consider capturing:
IP Addresses (internal and external)
Human and non-human accounts
Geographical data - this is important to match up to known threats (nation state or otherwise)
Success AND failures
Consider creating a watchlist of known entities (users, IPs) that should be able to access your AI and one for approved geographical locations. Using an editable watchlist enables you to quickly adjust your detections should the threat landscape change.
Microsoft Sentinel users, see: Monitor Azure Open AI Deployments with Microsoft Sentinel
How to mitigate
Mitigation for this type of attack is generally considered precautionary steps to avoid it in the first place. To mitigate a prompt injection attack, both developers and users should take appropriate precautions. Here are some steps to follow:
Input validation: Implement strict validation checks on user inputs to filter out malicious content, ensuring only valid and safe prompts are passed to the AI model.
Sanitization: Sanitize user inputs to remove or neutralize potentially harmful elements before processing them in the AI system.
Rate limiting: Apply rate limiting on user requests to prevent excessive or rapid attempts at injecting malicious prompts, making it harder for attackers to exploit the system.
Monitoring and logging: Monitor and log user inputs and AI responses to identify suspicious patterns, enabling early detection of potential prompt injection attacks.
Regular updates and patches: Keep your AI models and related software up to date, applying security patches and updates to minimize vulnerabilities.
User education: Educate users about the risks of prompt injection attacks, encouraging them to be cautious when providing input to AI systems and to report any suspicious behavior.
Secure AI model training: Ensure your AI models are trained on high-quality, diverse, and reliable data sources to reduce the chances of the model producing harmful outputs.
Phish Resistant MFA: For organizations developing their own AI apps, make sure to use proper identity mechanisms.
Trusted devices/applications: Ensure only trusted devices and applications are granted access.
Data Loss Protection (DLP): Protect sensitive corporate data from leaving the company due to user negligence, mishandling of data, or malicious intent.
By implementing these measures, you can reduce the risk of prompt injection attacks and enhance the overall security of your AI systems. To defend against prompt injection attacks, developers and researchers need to employ robust security measures, conduct thorough testing and validation, and implement mechanisms to detect and mitigate potential risks associated with manipulated prompts.
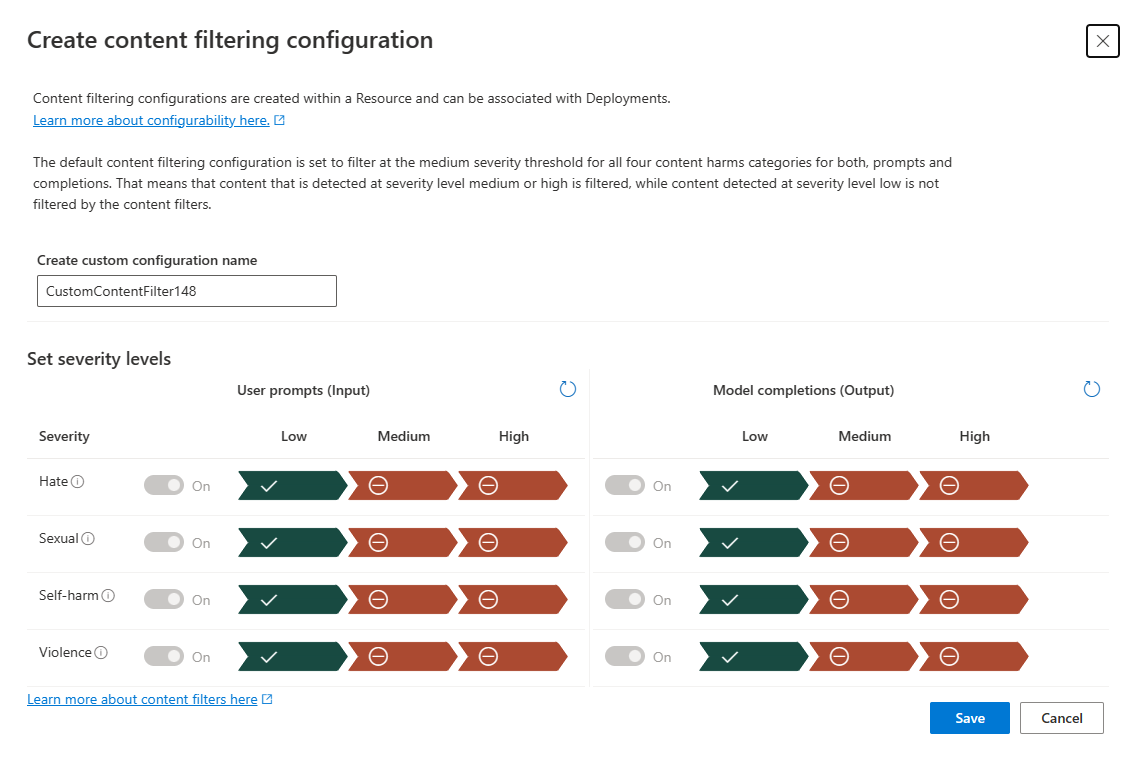
EXTRA: Content Filtering
One other thing to consider it developing a strong content filtering policy. As the data flows into the modern SIEM, outliers are identified, and detections and alerts are created, a part of mitigation that can help is to develop a better content filtering strategy. Azure OpenAI, for example, provides a stock feature for quickly adjusting content filtering. To create a fully customizable version, customers need to request full access to their own filtering.
See:
Azure OpenAI Service content filtering
Preventing abuse and harmful content generation
[Want to discuss this further? Hit me up on Twitter or LinkedIn]
[Subscribe to the RSS feed for this blog]
[Subscribe to the Weekly Microsoft Sentinel Newsletter]
[Subscribe to the Weekly Microsoft Defender Newsletter]
[Subscribe to the Weekly Azure OpenAI Newsletter]
[Learn KQL with the Must Learn KQL series and book]
[Learn AI Security with the Must Learn AI Security series and book]